# 简单Java爬虫
本文作者:程序员飞云
# 仅作为学习参考
# 引入依赖
<dependency>
<!-- jsoup HTML parser library @ https://jsoup.org/ -->
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.15.3</version>
</dependency>
2
3
4
5
6
7
# 1. 爬取bing的图片
第一步先找到bing的每个图片对应的标签
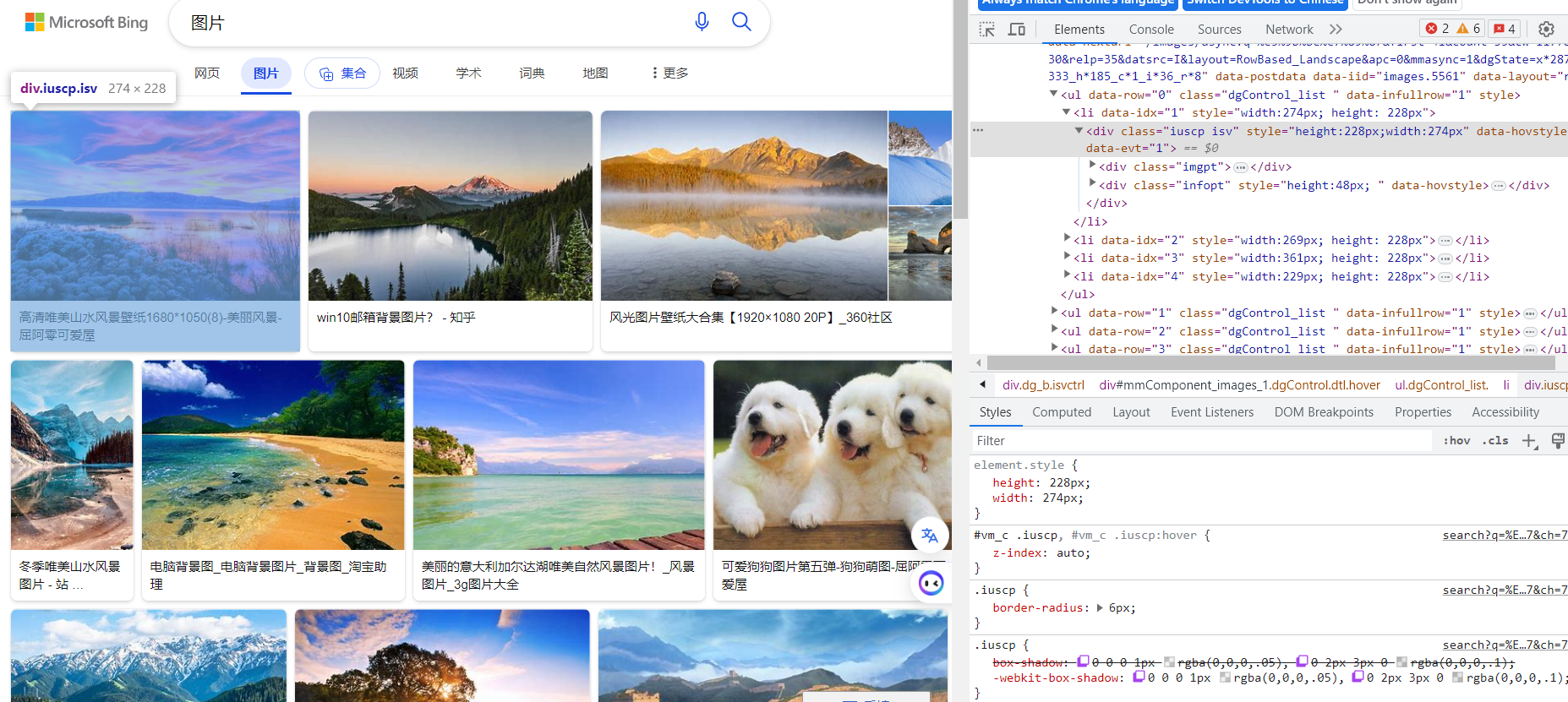
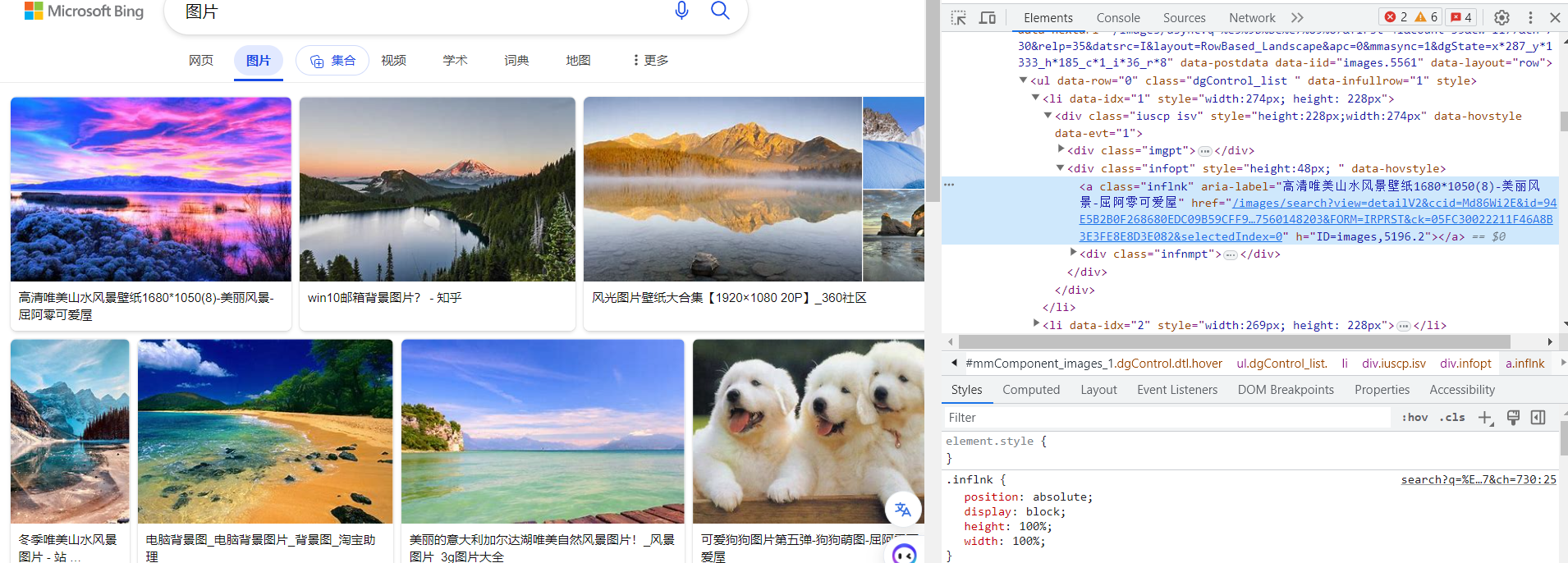 例如图片的标签是 iuscp isv
图片标题的标签是 inflnk
核心就是先找到响应标签
例如图片的标签是 iuscp isv
图片标题的标签是 inflnk
核心就是先找到响应标签
# 1.1 先写一个请求类
用于发送json请求
@Data
public class RandomPictureRequest {
private String searchText;
}
2
3
4
# 1.2 实体类
用于存储图片信息,包含url和标题
@Data
public class Picture implements Serializable {
private static final long serialVersionUID = 3946514657018193905L;
private String title;
private String url;
}
2
3
4
5
6
# 1.3 controller编写
这里我使用了自定义的返回类,可以直接使用String返回,最后结果直接返回list.get(0) 这里面的pageSize是一个随机页数,保证能够获取到随机的照片,也可以自己指定。
@RequestMapping( "/picture" )
@RestController
public class PictureController {
/**
* 随机抓取必应上的图片
*
* @param randomPicture
* @return
*/
@PostMapping( "/randomPicture" )
public BaseResponse<Picture> randomPicture(@RequestBody RandomPictureRequest randomPicture) {
if (randomPicture == null) {
throw new BusinessException(ErrorCode.PARAMS_ERROR);
}
// 获取搜索文本
String searchText = randomPicture.getSearchText();
int pageSize ;
Random random = new Random();
pageSize = random.nextInt(10);
String url = String.format("https://www.bing.com/images/search?q=%s&first=%s", searchText, pageSize);
// 发送请求
Document doc = null;
try {
doc = Jsoup.connect(url)
.header("Referer", "https://www.bing.com/")
.timeout(1000)
.get();
} catch (IOException e) {
throw new RuntimeException("输入错误");
}
List<Picture> list = new ArrayList<>();
// 获取标签
Elements select = doc.select(".iuscp.isv ");
for (Element element : select) {
// 图片地址
String s = element.select(".iusc").get(0).attr("m");
Map map = JSONUtil.toBean(s, Map.class);
String murl = (String) map.get("murl");
// 取标题
String title = element.select(".inflnk").get(0).attr("aria-label");
Picture picture = new Picture();
picture.setTitle(title);
picture.setUrl(murl);
list.add(picture);
}
// 返回第一个值
return ResultUtils.success(list.get(0));
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
目前的不足,对于有防盗链的照片无法展示
# 2. 爬取豆瓣的热门电影
 首先先打开F12找到每个电影所在的区域,可以看到是在li元素标签下面ui-slide-item s,所以选择的标签就是li.ui-slide-item,然后再从element里面去出对应的标签,例如data-title,标题
首先先打开F12找到每个电影所在的区域,可以看到是在li元素标签下面ui-slide-item s,所以选择的标签就是li.ui-slide-item,然后再从element里面去出对应的标签,例如data-title,标题
String url = "https://movie.douban.com/";
Document document = null;
try {
document = Jsoup.connect(url).get();
} catch (IOException e) {
e.printStackTrace();
}
Elements elements = document.select("li.ui-slide-item");
for (Element element : elements) {
// 标题
String title = element.attr("data-title");
// 发行时间
String release = element.attr("data-release");
// 评分
String rate = element.attr("data-rate");
// 主演
String star = element.attr("data-star");
// 地址
String trailer = element.attr("data-trailer");
// 卖票地址
String ticket = element.attr("data-ticket");
// 时长
String duration = element.attr("data-duration");
// 发行区域
String region = element.attr("data-region");
// 导演
String director = element.attr("data-director");
// 演员
String actors = element.attr("data-actors");
System.out.println("电影名字:" + title);
System.out.println("发行时间" + release);
System.out.println("评分"+rate);
System.out.println("地址"+trailer);
System.out.println("时长"+duration);
System.out.println("发行地区"+region);
System.out.println("主演"+actors);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
# 3. 豆瓣最受关注
先找到整个布局的部分,list-col2,里面存储着相应的元素标签
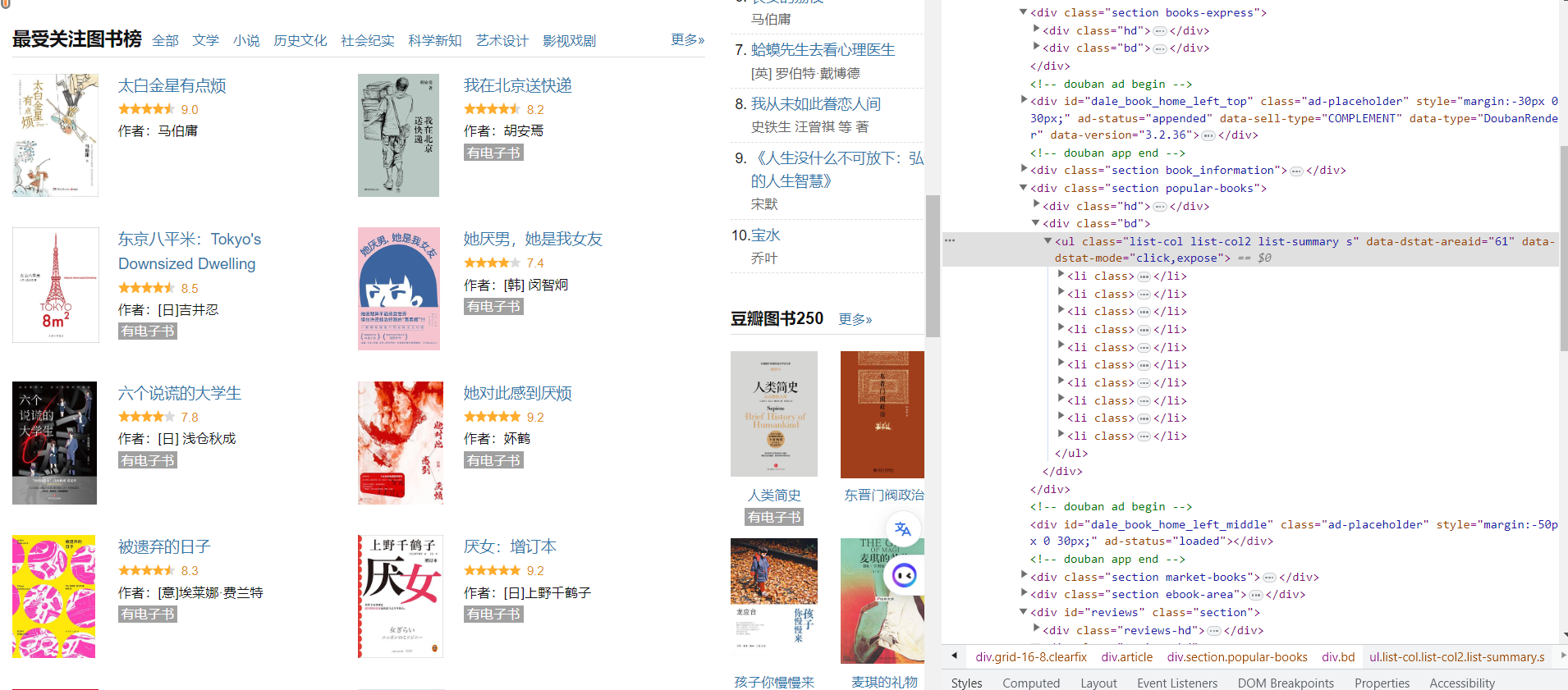 所以document的select标签就是ul.list-col2 li,意思是选择ul里面标签list-col2,然后选择里面的li
li里面分成两个部分,包含cover和info,我这里取出info里面的信息
所以document的select标签就是ul.list-col2 li,意思是选择ul里面标签list-col2,然后选择里面的li
li里面分成两个部分,包含cover和info,我这里取出info里面的信息

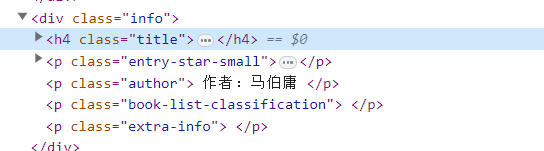
标题通过h4.title里面的a标签获取 作者直接通过p.author获取 里面的评分需要两层获取,先获取p标签,然后获取limian的span标签p.entry-star-small span.average-rating
public BaseResponse<String> famousDouBanBook(){
String url = "https://book.douban.com/";
Document document = null;
try {
document = Jsoup.connect(url).get();
} catch (IOException e) {
e.printStackTrace();
}
System.out.println(document);
Elements elements = document.select("ul.list-col2 li");
for (Element element : elements) {
String title = element.select("h4.title a").text();
String coverUrl = element.select("div.cover img").attr("src");
String rate = element.select("p.entry-star-small span.average-rating").text();;
String author = element.select("p.author").text();
System.out.println("书名:" + title);
System.out.println("封面:" + coverUrl);
System.out.println("评分:" + rate);
System.out.println("作者:" + author);
System.out.println("------------------------");
}
return ResultUtils.success("ok");
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
# 4. 99健康网
地址 https://yqk.99.com.cn/yq/type/list-300-9.html
 这个网站有点朴素,列表展示使用的div,导致获取联系电话的时候 需要使用:contains伪类来确保只提取包含"联系电话"文本的元素,而且取出来的数据是以间隔存储的,所以以下方式需要手动将间隔分离成不同的对象存储
这个网站有点朴素,列表展示使用的div,导致获取联系电话的时候 需要使用:contains伪类来确保只提取包含"联系电话"文本的元素,而且取出来的数据是以间隔存储的,所以以下方式需要手动将间隔分离成不同的对象存储

public static void main(String[] args) {
String url = "https://yqk.99.com.cn/yq/type/list-300-9.html";
Document document = null;
try {
document = Jsoup.connect(url).get();
} catch (IOException e) {
e.printStackTrace();
}
Elements elements = document.select("div.list_left > div");
List<CrawlCompanyInfo> companyInfoList = new ArrayList<>();
for (Element element : elements) {
String companyName = element.select("div.pro_title a").text();
String companyPhoneNumber = element.select("div.pro_text span.text01:contains(联系电话)").text();
companyPhoneNumber = companyPhoneNumber.replace("[联系电话]:", "");
CrawlCompanyInfo companyInfo = new CrawlCompanyInfo();
companyInfo.setCompanyName(companyName);
companyInfo.setPhoneNum(companyPhoneNumber);
companyInfoList.add(companyInfo);
}
for (CrawlCompanyInfo companyInfo : companyInfoList) {
System.out.println("Company Name: " + companyInfo.getCompanyName());
System.out.println("Phone Number: " + companyInfo.getPhoneNum());
System.out.println("-------------------");
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
修改,既然数据是聚合在一起,然就可以采用hashmap存储对应的元素,然后已间隔分开存储
public static void main(String[] args) {
String url = "https://yqk.99.com.cn/yq/type/list-300-9.html";
Document document = null;
try {
document = Jsoup.connect(url).get();
} catch (IOException e) {
e.printStackTrace();
}
Elements elements = document.select("div.list_left > div");
List<HashMap<String, String>> companyInfoList = new ArrayList<>();
for (Element element : elements) {
String companyName = element.select("div.pro_title a").text();
String companyPhoneNumber = element.select("div.pro_text span.text01:contains(联系电话)").text();
companyPhoneNumber = companyPhoneNumber.replace("[联系电话]:", "");
HashMap<String, String> map = new HashMap<>();
map.put("companyName", companyName);
map.put("phoneNum", companyPhoneNumber);
companyInfoList.add(map);
}
HashMap<String, String> map = companyInfoList.get(0);
String companyName = map.get("companyName");
String phoneNum = map.get("phoneNum");
String[] companyNames = companyName.split(" ");
String[] phoneNums = phoneNum.split(" ");
List<CrawlCompanyInfo> crawlCompanyInfoList = new ArrayList<>();
for (int i = 0; i < companyNames.length; i++) {
CrawlCompanyInfo companyInfo = new CrawlCompanyInfo();
companyInfo.setCompanyName(companyNames[i]);
companyInfo.setPhoneNum(phoneNums[i]);
crawlCompanyInfoList.add(companyInfo);
}
for (CrawlCompanyInfo companyInfo : crawlCompanyInfoList) {
System.out.println("Company Name: " + companyInfo.getCompanyName());
System.out.println("Phone Number: " + companyInfo.getPhoneNum());
System.out.println("-------------------");
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
# 5. 爬取99网站药店公司信息
public static void main(String[] args) {
String url = "https://ypk.99.com.cn/yaodian/";
Document document = null;
try {
document = Jsoup.connect(url).get();
} catch (IOException e) {
e.printStackTrace();
}
Elements elements = document.select("dl");
List<CrawlSaleInfo> list = new ArrayList<>();
for (Element element : elements) {
String saleName = element.select("div.pmy-name b a").text();
Elements phoneElements = element.select("div.pmy-name p");
String phoneNumber = phoneElements.size() > 0 ? phoneElements.get(0).text().replace("联系电话:", "") : "";
CrawlSaleInfo crawlSaleInfo = new CrawlSaleInfo();
crawlSaleInfo.setPhoneNum(phoneNumber);
crawlSaleInfo.setSaleName(saleName);
list.add(crawlSaleInfo);
}
list.stream()
.filter(crawlSaleInfo -> !crawlSaleInfo.getSaleName().isEmpty() && !crawlSaleInfo.getPhoneNum().isEmpty())
.forEach(System.out::println);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
# 6. 爬取99网站药品信息
public static void main(String[] args) {
String url = "https://ypk.99.com.cn/";
Document document = null;
try {
document = Jsoup.connect(url).get();
} catch (IOException e) {
e.printStackTrace();
}
Elements elements = document.select("div.wrap2-right ul li");
for (Element element : elements) {
String title = element.select("a.wrap2-name").attr("title");
String src = element.select("img").first().attr("src");
String paragraph = element.select("p").text();
System.out.println("Title: " + title);
System.out.println("Src: " + src);
System.out.println("Paragraph: " + paragraph);
System.out.println("--------------------");
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21